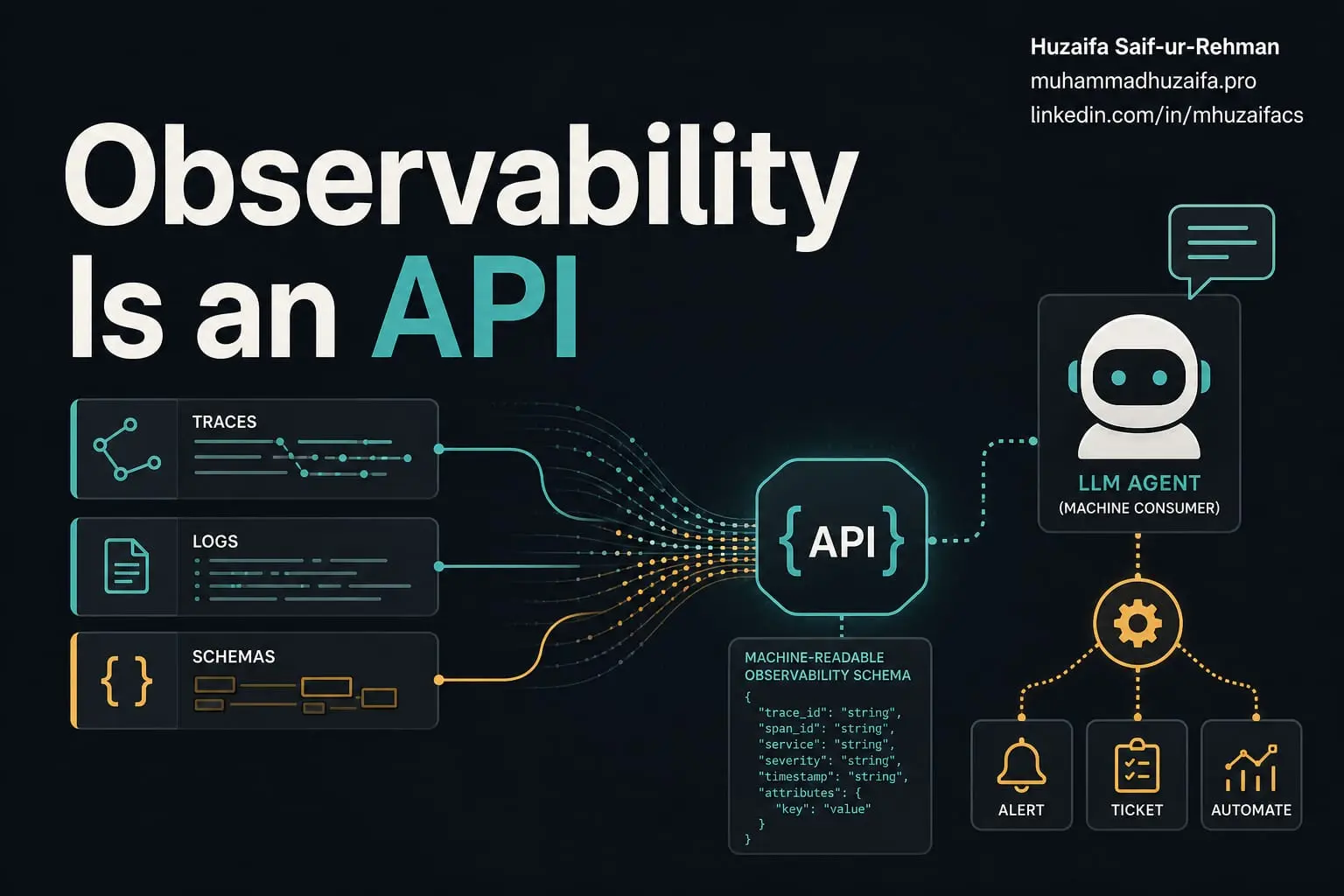
Agent Evaluation: Why Tool Traces and Verification Matter
Published on

Long-context agent evaluation is a different problem from judging one clean final answer.
The useful framing from Agent Judge is that production agents should be evaluated on the work they did across the whole trajectory, not only the last response. A normal LLM judge can miss the parts that determine whether an agent is reliable: did it search the right places, did it verify state after taking an action, and did it adjust when feedback changed the rubric?
A few takeaways I would keep in mind when building or reviewing agentic systems:
-
Search quality matters. An agent that answers confidently without looking in the right systems is not production-ready.
-
Verification should be explicit. If the agent changes state in a real system, the eval should check whether it confirmed the result.
-
Rubrics need to evolve from feedback. Static evals help, but harder scenarios need criteria that reflect real failure modes.
For production workflows, evidence should be part of the evaluation contract. That feels especially relevant for teams moving from demos to agents that touch real customer data, tickets, inboxes, billing, or deployments.
What do you currently trust more for agent evals: final answer quality, tool trace review, or outcome verification?