
Staff Software Engineer
Huzaifa Saif-ur-RehmanAI Engineering & LLM Development
Huzaifa Saif-ur-Rehman is a staff software engineer specializing in Laravel, PHP, JavaScript, DevOps, SaaS architecture, and API integrations.
Laravel Live Pakistan 2024
@Pearl Continental Lahore, Pakistan

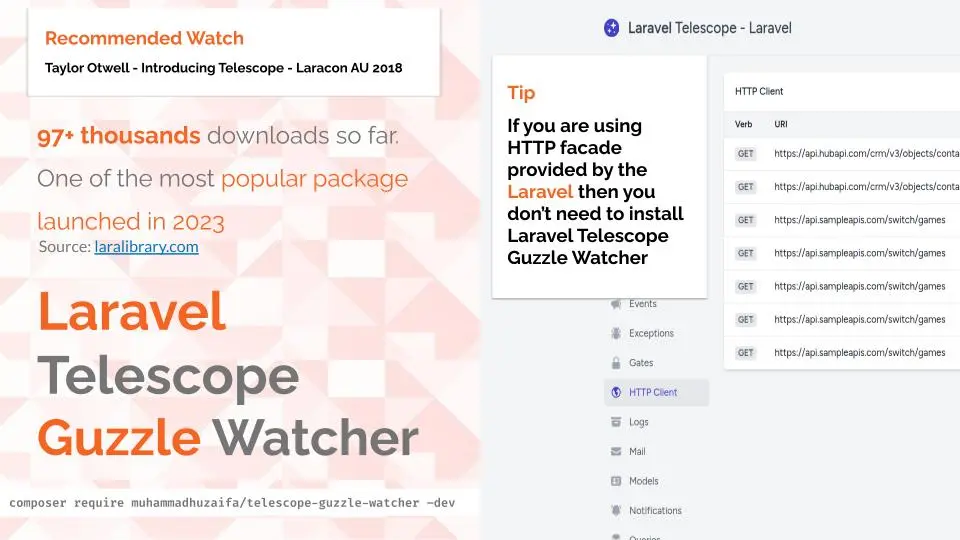
Presenting Telescope Guzzle Watcher
@Laravel Live Pakistan 2024, Pakistan
COMPUTAN Team Annual Meetup
@Lahore HeadOffice, Pakistan

Laravel Live Pakistan 2024
@Pearl Continental Lahore, Pakistan

DEVOPS Meetup Lahore
(Open Source Foundation Pakistan) @FAST-NUCES, Lahore

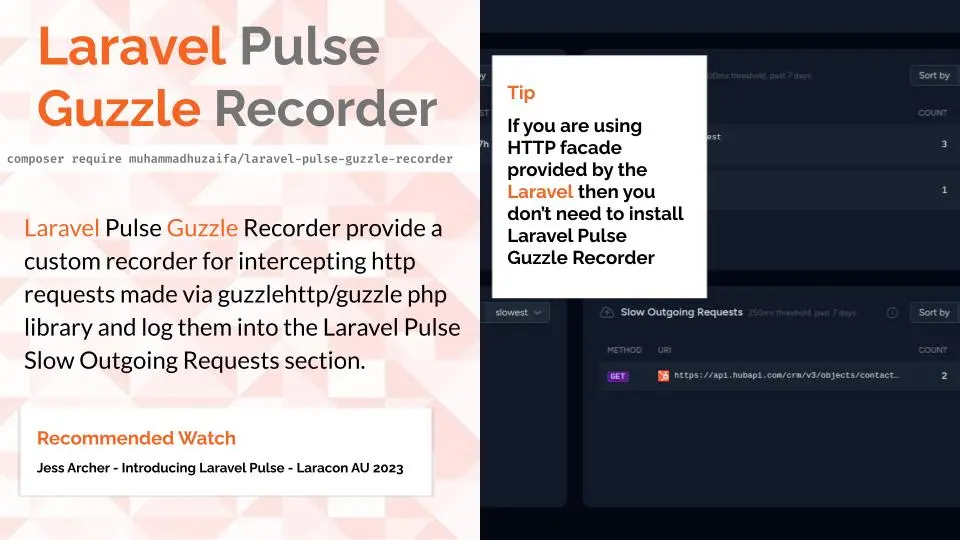
Presenting Pulse Guzzle Recorder
@Laravel Live Pakistan 2024, Pakistan
Laravel Live Pakistan 2024
@Pearl Continental Lahore, Pakistan

Laravel Live Pakistan 2024
@Pearl Continental Lahore, Pakistan

Laravel Live Pakistan 2024
@Pearl Continental Lahore, Pakistan

COMPUTAN Annual Team Leads Dinner
@Monal Lahore, Pakistan

AI engineering for production
AI features your users can trust, engineered, not vibe-coded. LLM features, RAG, and agents built with the same reliability discipline as a payment flow.
Wiring a prompt to an API is the easy part. Keeping an AI feature accurate, grounded in your data, controlled in what it can do, and honest about its costs is the part that breaks. I build LLM-powered features into Laravel and Node products, and I engineer them so they fail loudly and safely instead of quietly making things up.
What I build for you
Real, sellable AI engineering, not a chatbot bolted onto a marketing page.
LLM feature integration
Summarize, classify, extract, chat, and copilot features built into your existing product, with proper API design, streaming, and cost controls so a runaway prompt loop never becomes a runaway bill.
RAG systems
Retrieval-augmented generation that grounds answers in your own data: embeddings, vector search, retrieval, and the guardrails that keep responses traceable to a source instead of guessed.
Agentic workflows
Multi-step agents that plan, call tools, and act across a real business task, with explicit limits on what the agent is allowed to do. The hard part is control and reliability over many steps, which is exactly where most agent demos fall apart.
Prompt engineering, evals & guardrails
Evaluation harnesses that score the model on real examples, guardrails that constrain output and behavior, and observability so AI features fail loudly. An AI feature that fails quietly is worse than no feature.
Built with frontier hosted models (Claude, OpenAI) and open-source or self-hosted models, chosen per task on cost, quality, latency, and privacy. Not married to one vendor.
How I engineer AI, not vibe coding
The difference between AI engineering and vibe coding is discipline and verification. The model accelerates the work; it does not get to decide what "done" means.
Multiple models, holding each other honest
I run several frontier and open-source models that review each other's work, so output is cross-checked rather than trusted on the first pass. Disagreement between models is a signal, not noise.
One engineering standard, applied everywhere
Every model I use is held to a centralized, version-controlled engineering standard, so the same conventions, security rules, and quality bar apply on every task instead of drifting from prompt to prompt.
Privacy-first, self-hosted when it matters
For sensitive data I run self-hosted open models in Docker, including a voice-driven workflow for hands-free engineering, so nothing has to leave your environment to get the work done.
What you can expect
Evals before ship, not after complaints
AI features are scored against real examples before they go live, and watched in production, so a quality regression surfaces as a number, not as a support ticket.
Cost transparency, no black boxes
You see what each call costs, where the limits are, and how the feature behaves. No mystery spend, and no "trust me, the AI handles it."
Your data stays yours
Self-hosted models for sensitive work, and provider configurations that keep your data out of training when using hosted models. Privacy is a design input, not an afterthought.
Built into a real product, to real standards
Most AI work lands inside an existing Laravel or Node app, built to the same money-path and reliability standards as the rest of the system, not a demo stapled on the side.
FAQ
Frequently asked questions
Both, and they are different things. I integrate LLM-powered features into products — retrieval-augmented answers, classification, extraction, chat, copilots — and I also engineer my own delivery with AI rigor. What I sell you is the former: production AI features that hold up. The latter is just why I can build them faster without cutting corners.
Retrieval-augmented generation grounds an LLM's answers in your own data — your docs, records, or knowledge base — instead of letting it guess. You need it when answers must be correct and traceable to a source. I build the full path: embeddings, vector search, retrieval, and the guardrails that keep answers grounded.
Evals and guardrails. Before anything ships, I build an evaluation harness that scores the model on real examples, add guardrails that constrain what it can output or do, and wire in observability so failures are visible, not silent. An AI feature that fails quietly is worse than no feature.
Frontier hosted models (Claude, OpenAI) and open-source or self-hosted models, chosen per task on cost, quality, latency, and privacy. For sensitive data I run self-hosted models in Docker so nothing leaves your environment. I am not married to one vendor.
Discipline and verification. I run multiple models that review each other's work, hold every one of them to a centralized, version-controlled engineering standard, and verify output against real criteria before it ships. The AI accelerates the work; it does not get to decide what "done" means.
Yes. Most of my AI work lands inside existing products — a new endpoint, a background job, a copilot in the UI — built to the same money-path and reliability standards as the rest of the app, with cost controls so a runaway prompt loop never becomes a runaway bill.
Yes. I build multi-step agent workflows where a model plans, calls tools, and acts across several steps, with explicit limits on what it is allowed to do. The engineering challenge is control and reliability over many steps, which is exactly where most agent demos fall apart and where I focus.
No. I design for data privacy: self-hosted open models in Docker when the data is sensitive, and providers and configurations that exclude your data from training when using hosted models. Your data stays yours.
Plan your AI feature
Tell me the use case, what data it needs to reason over, and what must never go wrong. I will help you turn it into a feature that holds up in production.