Observability for AI Agents: Why Your Traces Need to Become an API
Published on
The more agentic systems we build, the more I think observability needs a small shift in mindset.
For years, metrics, logs, and traces were designed around a human workflow: something breaks, an engineer opens a dashboard, scans the logs, jumps through traces, and builds a mental model of what happened.
That model still matters. But LLMs and agents are starting to consume the same operational data directly. In that world, traces may become less of a debugging artifact and more of an interface.
A few takeaways I liked from this angle:
-
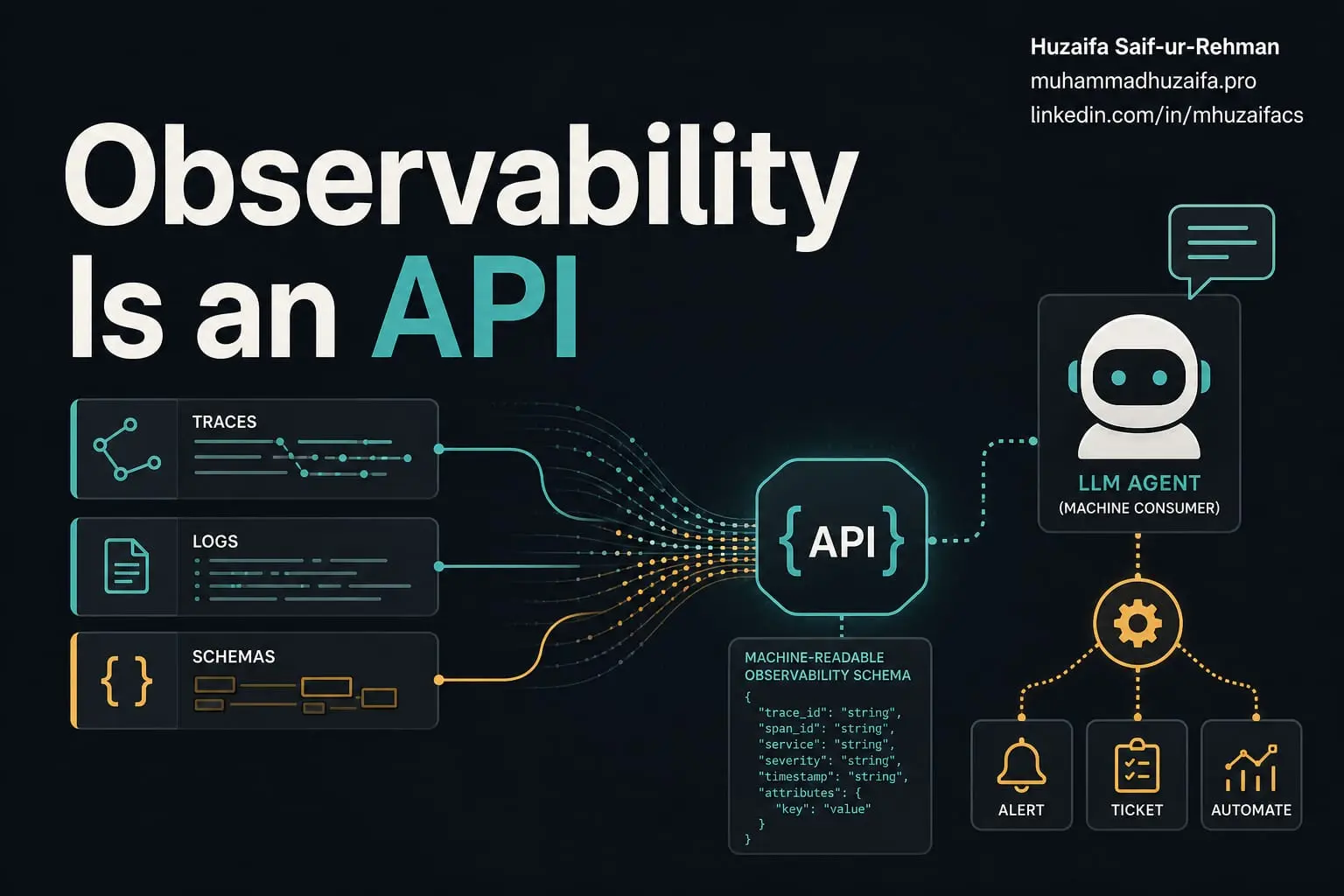
Traces are probably the most useful entry point for agents because they preserve flow, timing, causality, and context.
-
Trace schemas should be treated like APIs. If agents depend on them, they need stable names, clear meanings, versioning, and documentation.
-
Human-readable observability is not enough. Machine-readable observability needs predictable structure, not clever labels and inconsistent conventions.
-
This applies beyond infra teams. Laravel apps, queues, jobs, webhooks, payments, and third-party integrations all benefit when traces explain intent, state, and failure context clearly.
If an agent is going to help debug production, the trace is part of the contract.